 Hadoop to platforma programistyczna oparta na Java, która obsługuje przetwarzanie i przechowywanie bardzo dużych zbiorów danych w klastrze z tanich maszyn. Był to pierwszy duży projekt open source w dużym boisku danych i jest sponsorowany przez Apache Software Foundation.
Hadoop to platforma programistyczna oparta na Java, która obsługuje przetwarzanie i przechowywanie bardzo dużych zbiorów danych w klastrze z tanich maszyn. Był to pierwszy duży projekt open source w dużym boisku danych i jest sponsorowany przez Apache Software Foundation.
Hadoop 2.7 składa się z czterech warstw:
- Hadoop Common jest zbiorem narzędzi i bibliotek, które obsługują inne moduły Hadoop.
- HDFS, co oznacza Hadoop Distributed File System, jest odpowiedzialny za utrzymanie danych na dysku.
- YARN, skrócono od Yet Another Resource Negotiator, to “system operacyjny” dla HDFS.
- MapReduce to oryginalny model przetwarzania dla klastrów Hadoop. On rozdziela pracę wewnątrz klastra lub mapy, a następnie organizuje i zmniejsza rezultaty od węzłów w odpowiedzi na zapytanie. Wiele innych modeli przetwarzania są dostępne dla wersji 2.x Hadoop.
Klastry Hadoop są stosunkowo skomplikowane w konfiguracji, więc projekt obejmuje tryb offline, który jest przeznaczony do nauki o Hadoop, wykonywania prostych operacji i debugowania.
W tym tutorialu, będziemy instalować Hadoop w trybie offline i uruchamiać jeden z przykładów programów MapReduce w celu sprawdzenia instalacji.
Wymagania
Aby kontynuować, potrzebujesz:
- Serwer Ubuntu 16.04 z użytkownikiem innym niż root z uprawnieniami sudo: możesz dowiedzieć się więcej o tym, jak utworzyć użytkownika z tymi uprawnieniami w naszym tutorialu Wstępna Konfiguracja serwera z Ubuntu 16.04.
Po spełnieniu tego warunku, jesteś gotowy do zainstalowania Hadoop i jego zależności.
Krok #1 – Instalacja Java
Aby rozpocząć, zaktualizujemy naszą listę pakietów:
sudo apt-get update
Następnie będziemy instalować OpenJDK, domyślne Java Development Kit na Ubuntu 16.04.
sudo apt-get install default-jdk
Po zakończeniu instalacji, sprawdź wersję.
java –version
openjdk version "1.8.0_91" OpenJDK Runtime Environment (build 1.8.0_91-8u91-b14-3ubuntu1~16.04.1-b14) OpenJDK 64-Bit Server VM (build 25.91-b14, mixed mode)
Dane Output pokazują, że OpenJDK został pomyślnie zainstalowany.
Krok #2 – Instalacja Hadoop
Za pomocą Java, odwiedzimy stronę Apache Hadoop Releases, aby znaleźć najnowszą stabilną wersję. Postępuj zgodnie z binary dla aktualnej wersji: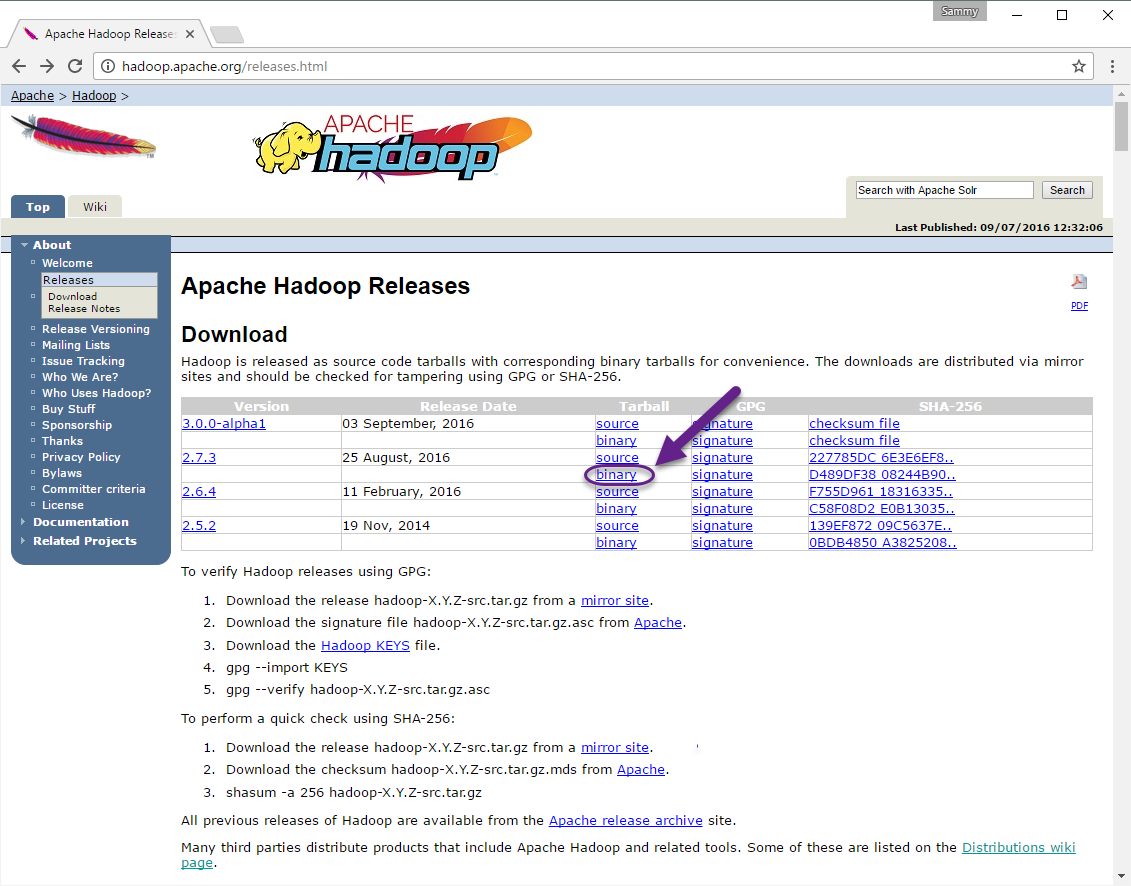
Na następnej stronie kliknij prawym przyciskiem myszy i skopiuj link do najnowszej stabilnej wersji binarnej.
Na serwerze użyjemy wget, aby ją pobrać:
wget http://apache.mirrors.tds.net/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz
W celu upewnienia się, że plik który chcemy pobrać nie został zmieniony, zrobimy szybki test używając SHA-256. Wróć na stronę Apache Hadoop Releases, a następnie przejdź do linku Apache: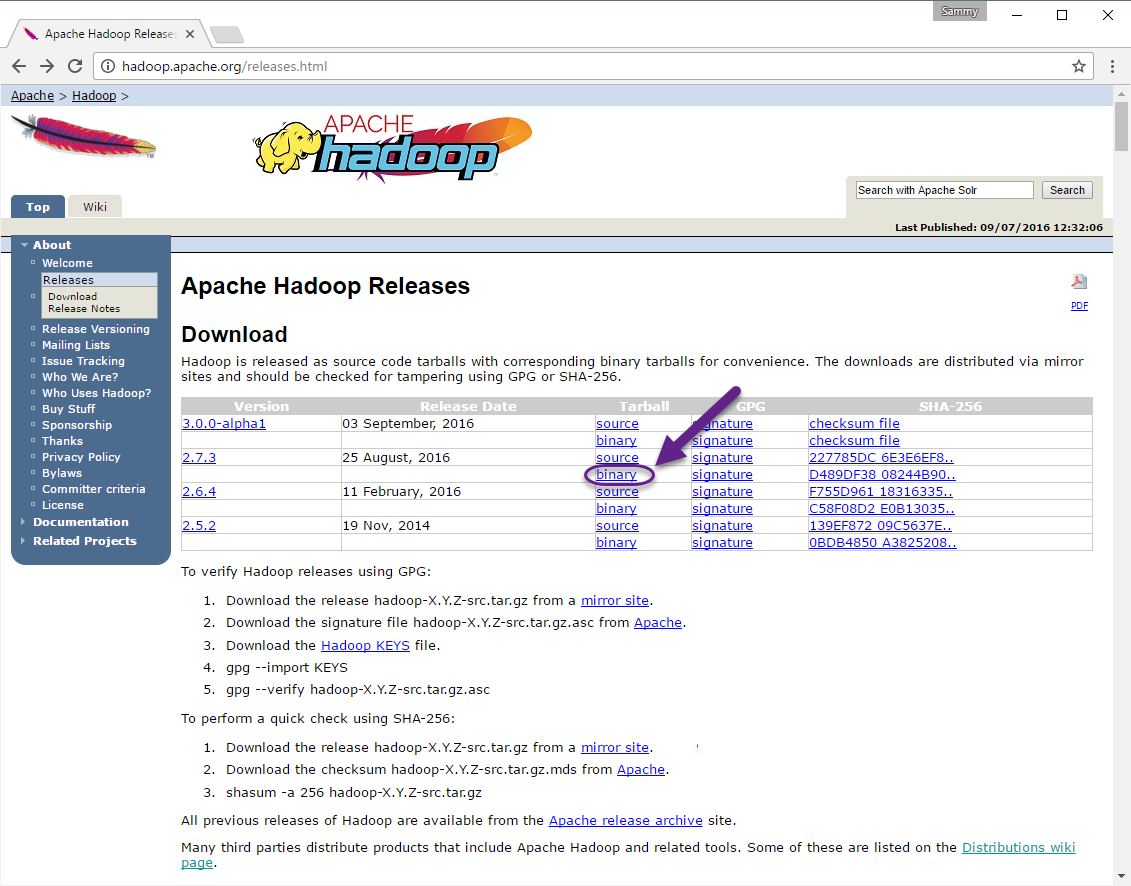
Podaj katalog dla pobranej wersji:
Wreszcie, zlokalizuj plik .mds który został pobrany, a następnie skopiuj link do odpowiedniego pliku: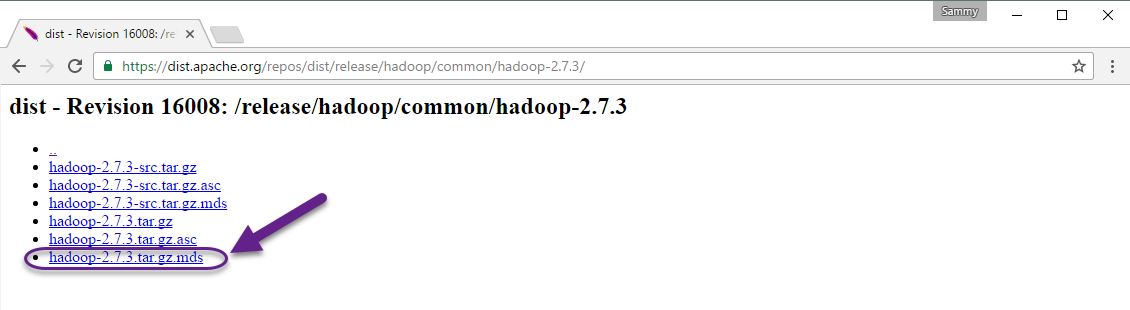
Znowu, kliknij prawym przyciskiem myszy, aby skopiować lokalizację pliku, a następnie użyj wget do przeniesienia pliku:
wget https://dist.apache.org/repos/dist/release/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz.mds
Następnie należy uruchomić weryfikację:
shasum -a 256 hadoop-2.7.3.tar.gz
d489df3808244b906eb38f4d081ba49e50c4603db03efd5e594a1e98b09259c2 hadoop-2.7.3.tar.gz
Porównaj tą wartość z wartością SHA-256 w pliku .mds:
cat hadoop-2.7.3.tar.gz.mds
... hadoop-2.7.3.tar.gz: SHA256 = D489DF38 08244B90 6EB38F4D 081BA49E 50C4603D B03EFD5E 594A1E98 B09259C2 ...
Teraz, gdy jesteśmy pewni, że plik nie został uszkodzony lub zmieniony, użyjemy polecenia tar z flagą -x aby wyodrębnić, -z aby rozpakować, -v dla bardziej szczegółowego wyjścia i -f aby określić, co możemy pozyskać z pliku. Użyj tab-completion lub podaj odpowiedni numer wersji w polecenie poniżej:
tar -xzvf hadoop-2.7.3.tar.gz
Wreszcie, rozpakujemy pliki w /usr/local, odpowiednie miejsce dla lokalnie zainstalowanego oprogramowania. Zmień numer wersji w razie potrzeby, aby dopasować do wersji którą pobrałeś.
sudo mv hadoop-2.7.3 /usr/local/hadoop
Z oprogramowaniem jesteśmy gotowi, aby skonfigurować swoje środowisko.
Krok #3 – Konfiguracja Home Hadoop Java
Hadoop wymaga aby ustawić ścieżkę do Javy, albo jako zmienna środowiskowa lub w pliku konfiguracyjnym.
Ścieżka do Javy, /usr/bin/java jest dowiązaniem do /etc/alternatives/java, który z kolei jest dowiązaniem symbolicznym do domyślnego pliku binarnego Java. Będziemy używać readlink z flagą -f, aby śledzić każde dowiązanie symboliczne w każdej części ścieżki, rekurencyjnie. Następnie użyjemy sed do wykończenia bin/java z danych wyjściowych, aby otrzymać prawidłową wartość JAVA_HOME.
Aby znaleźć domyślną ścieżkę Java
readlink -f /usr/bin/java | sed "s:bin/java::"
/usr/lib/jvm/java-8-openjdk-amd64/jre/
Można skopiować te dane, aby zainstalować Home Hadoop Java do tej konkretnej wersji, co gwarantuje, że jeżeli domyślna Java się zmienia, wartość ta zmieniać się nie będzie. Alternatywnie, można użyć polecenia readlink dynamicznie w pliku tak, że Hadoop automatycznie użyje każdą wersję Java, ustawioną jako domyślną.
Aby rozpocząć, otwórz hadoop-env.sh:
sudo nano /usr/local/hadoop/etc/hadoop/hadoop-env.sh
Następnie, wybierz jedną z następujących opcji:
Opcja 1: Ustawienie statycznej wartości
. . . #export JAVA_HOME=${JAVA_HOME} export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/jre/ . . .
Opcja 2: Stosowanie readlink dla ustawienia dynamicznej wartości
. . . #export JAVA_HOME=${JAVA_HOME} export JAVA_HOME=$(readlink -f /usr/bin/java | sed "s:bin/java::") . . .
Krok #4 – Uruchomienie Hadoop
Teraz możemy uruchomić Hadoop:
/usr/local/hadoop/bin/hadoop
Usage: hadoop [--config confdir] [COMMAND | CLASSNAME]
CLASSNAME run the class named CLASSNAME
or
where COMMAND is one of:
fs run a generic filesystem user client
version print the version
jar <jar> run a jar file
note: please use "yarn jar" to launch
YARN applications, not this command.
checknative [-a|-h] check native hadoop and compression libraries availability
distcp <srcurl> <desturl> copy file or directories recursively
archive -archiveName NAME -p <parent path> <src>* <dest> create a hadoop archive
classpath prints the class path needed to get the
credential interact with credential providers
Hadoop jar and the required libraries
daemonlog get/set the log level for each daemonTo oznacza, że pomyślnie skonfigurowaliśmy Hadoop do pracy w trybie offline. Możemy zapewnić, że to działa poprawnie, uruchamiając przykładowo program MapReduce. Aby to zrobić, należy utworzyć katalog o nazwie input w naszym katalogu domowym i skopiować do niego pliki konfiguracyjne Hadoop, aby wykorzystać te pliki jako nasze dane.
mkdir ~/input
cp /usr/local/hadoop/etc/hadoop/*.xml ~/input
Następnie możemy użyć następującego polecenia, aby uruchomić program MapReduce hadoop-mapreduce-examples, archiwum Javy z kilkoma opcjami. Będziemy odwoływać się na grep program, jeden z wielu przykładów zawartych w hadoop-mapreduce-examples, a następnie w katalogu wejściowym input i katalogu wyjściowym grep_example. Program grep MapReduce będzie liczyć dopasowanie dosłowne słowa lub wyrażenia regularnego. Wreszcie, będziemy dostarczać wyrażenie regularne do znalezienia wystąpień słowa principal wewnątrz lub na końcu zdania deklaratywnego. Wyrażenie jest z uwzględnieniem wielkości liter, więc nie znajdzie słowo jeśli jest ono napisane z dużej litery na początku zdania:
/usr/local/hadoop/bin/hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar grep ~/input ~/grep_example 'principal[.]*'
Po zakończeniu zadania, będzie przedstawiona krótka informacja o tym, co zostało przetworzone i o napotkanych błędach, ale ta informacja nie zawiera rzeczywistych wyników.
. . .
File System Counters
FILE: Number of bytes read=1247674
FILE: Number of bytes written=2324248
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Map input records=2
Map output records=2
Map output bytes=37
Map output materialized bytes=47
Input split bytes=114
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=47
Reduce input records=2
Reduce output records=2
Spilled Records=4
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=61
Total committed heap usage (bytes)=263520256
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=151
File Output Format Counters
Bytes Written=37Uwaga: Jeśli katalog wyjściowy już istnieje, wystąpi błąd programu, a zamiast wyświetlanego podsumowania, Ouput będzie wyglądać tak:
. . . at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.hadoop.util.RunJar.run(RunJar.java:221) at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
Wyniki zapisywane są w katalogu wyjściowym, ich można sprawdzić, uruchamiając cat w katalogu wyjściowym:
cat ~/grep_example/*
6 principal 1 principal.
MapReduce znalazł jedno wystąpienie tego słowa principal i sześć przypadków, w których te słowo nie występuje. Uruchomienie przykładowego programu zweryfikowało, że nasza instalacja działa poprawnie i że nieuprzywilejowany użytkownik w systemie może uruchomić Hadoop do poszukiwania lub do debugowania.
Wniosek
W tym tutorialu, mamy zainstalowany Hadoop w trybie offline, który jest sprawdzany przez uruchamianie przykładowego programu. Aby dowiedzieć się jak pisać własne programy MapReduce, warto odwiedzić tutorial Apache Hadoop’s MapReduce. Gdy jesteś gotowy do utworzenia klastra, zobacz przewodnik Apache Foundation Hadoop Cluster Setup.