
Plik robots.txt jest plikiem tekstowym na serwerze lub hostingu. Zawiera on instrukcje z poleceniami dla robotów wyszukiwarek które strony należy dodawać do indeksu, które nie. Robots.txt jest tworzony zgodnie ze zdefiniowaną w dokumentacji składnią, a jego reguły są rozumiane przez roboty wszystkich wyszukiwarek. W przypadku braku tego pliku roboty przeskanują i dodadzą do indeksu wszystkie strony, co może negatywnie wpłynąć na pozycjonowanie strony www.
Czym jest robots.txt?
Specyfikacja pliku została stworzona wyłącznie dla robotów wyszukiwarek (Google, Bing, DuckDuckGo itd). Podczas odwiedzania witryny Robot lub bot najpierw próbuje pobrać zawartość robots.txt, a w przypadku jego braku działa zgodnie z ogólnym algorytmem skanowania strony, czyli po prostu skanuje wszystkie strony, które odnajdzie. Instrukcje umieszczone w pliku robots.txt, pozwalają:
- skonfigurować zakaz na indeksowanie stron,
- skonfigurować zakaz na indeksowanie wybranych katalogów,
- skonfigurować zakaz na skanowanie zasobów strony (obrazów, plików JS, CSS itp.),
- połączyć zakazy i pozwolenia do skanowania,
- skonfigurować reguły dla poszczególnych robotów/wyszukiwarek,
- określić główny adres URL strony,
- określić żądany interwał skanowania strony przez roboty,
- określić adres URL do mapy serwisu (np. sitemap.xml).
Najprostszy przykład pliku robots.txt, reguły którego stosowane kiedy takiego pliku nie ma:
# Brak ograniczeń na skanowanie: User-agent: * Disallow:
Taki kod będzie sugerował robotom nie skanować strony:
# Zakaz skanowania: User-agent: * Disallow: /
Czy jest potrzebny robots.txt?
Plik robots.txt jest potrzebny gdy chcemy:
- wyznaczyć listę stron, które chcemy mieć w wynikach wyszukiwania;
- zmniejszyć obciążenie na serwer przez roboty wyszukiwarek;
- wskazać główny URL strony (wersja z www czy bez);
- skierować robot do pliku z mapą strony (Sitemap);
- dodać reguły specjalne dla botów wyszukiwarek np. z wykorzystaniem RegExp.
Czasami roboty nie biorą pod uwagę reguły z pliku robots.txt przez błędy w składn. Oto najbardziej rozpowszechnione:
- rozmiar pliku powyżej dopuszczalnego rozmiaru (512 Kb dla Google);
- błędy w literówkach reguł lub linków;
- typ plik nie jest tekstowym i / lub zawiera niedopuszczalne symbole;
- brak dostępu do pliku przy zapytaniu do serwera.
Jak utworzyć plik robots.txt?
Plik robots.txt można utworzyć w zwykłym edytorze tekstowym na komputerze lub pry pomocy generatora online. Edytować możemy go w Notatniku lub Notepad++. Przykład zawartości robots.txt:
User-agent: * Disallow: /bin/ — nie indeksować strony z kategorii/folderu bin; Disallow: /search/ — nie indeksować linki ze strony wyszukiwań; Disallow: /admin/ — nie indeksować strony z panelu administracyjnego; Sitemap: https://strona.pl/sitemap-index.xml — link do mapy strony;
Do reguł w tym pliku czasami dodają również komentarze dla administratorów, które wpisują po znaku # w nowej linii. Roboty ignorują rą treść, przykład pliku z komentarzem:
User-agent: * Allow: / Host: www.strona.pl # za 2 dni host główny zostanie zmieniony
Jeżeli nie ma możliwości samodzielnego utworzenia tego pliku możemy skorzystać z generatorów robots.txt online, które tworzą plik według reguł i parametrów wskazanych na stronie internetowej narzędzia.
Wymagania do pliku robots.txt:
- plik powinien mieć rozszerzenie
txt, - nazwa pliku musi być małymi literami – robots,
- plik powinien znajdować się pod adresem domena/robots.txt,
- przy zapytaniu do pliku – serwer powinien zwracać kod 200 OK,
- rozmiar pliku nie powinien być większy od 500 Kb.
Algorytm tworzenia pliku
Aby poprawnie utworzyć plik dla strony, możemy postępować według następnego algorytmu:
- tworzymy standardowy dokument tekstowy z rozszerzeniem
txt, - zmieniamy nazwę na robots,
- otwieramy stworzony plik przy pomocy notatnika lub innego programu do edycji,
- dodajemy reguły oraz linki naszej strony,
- sprawdzamy poprawność składni pliku (np. poprzez https://technicalseo.com/tools/robots-txt/ ),
- jeżeli wszystko jest ok, wysyłamy plik poprzez FTP/sFTP na hosting do folderu głównego domeny,
- sprawdzamy czy jest dostępny pod linkiem domena/robots.txt.
Generator robots.txt
Jak pisaliśmy wcześniej można utworzyć plik robots.txt w narzędziach online, jednak taki serwis nie skonfiguruje plik pod naszą stronę, system CMS lub zainstalowane wtyczki. Dlatego taki plik najlepiej może skonfigurować tylko administrator lub osoba, która zajmuje się optymalizacją SEO.
Generator online – https://www.seoptimer.com/robots-txt-generator
User-agent i reguły w robots.txt
Reguła User-agent wskazuje dla jakich robotów zostały dodane reguły w tym bloku.В качестве значения директивы User-agent указывается конкретный тип робота или символ *. Например:
# Последовательность инструкций для робота YandexBot: User-agent: YandexBot Disallow: /
Lista najbardziej popularnych botów dla parametru User-agent:
- Googlebot
- Bingbot
- Slurp
- DuckDuckBot
- Baiduspider
- YandexBot
- ia_archiver
- Exabot
- Wielkość liter w parametrze User-agent nie ma znaczenia.
Obsługa User-agent
Aby wskazać że instrukcje poniżej są przeznaczone dla wszystkich robotów – stosujemy gwiazdkę *. Na przykład:
# Instrukcje i reguły dla wszystkich robotów wyszukiwarek: User-agent: * Disallow: /
Pomiędzy blokami reguł dla różnych robotów należy dodawać pustą linie:
User-agent: * Disallow: / User-agent: DuckDuckBot Allow: /
Przy czym warto zwracać uwagę na puste linie pomiędzy regułami dla jednego bota, reguły nie mogą się przerywać:
# Poprawna konfiguracja: User-agent: * Disallow: /administrator/ Disallow: /files/ # Zła konfiguracja: User-agent: * Disallow: /administrator/ Disallow: /files/
Należy zwrócić uwagę na to, że przy dodaniu instrukcji/reguł dla wybranego robota, pozostałe ogólne instrukcje będą ignorowane:
# Reguły dla robota Googlebot-Image: User-agent: Googlebot-Image Disallow: / Allow: /images/ # Instrukcje dla wszystkich robotów Google, oprócz Googlebot-Image User-agent: Google Disallow: /images/ # Instrukcje dla wszystkich robotów, oprócz robotów Google User-agent: * Disallow:
Reguła Disallow
Instrukcja Disallow stosuje się przy stworzeniu listy zakazów dla robotów, gdy chcemy zakazać robotowi dodawać do indeksu pewne strony lub foldery. Pierwszy symbol / (slash) wskazuje początek adresu URL, na przykład:
# Zakaz na skanowanie strony: User-agent: * Disallow: / # Zakaz na skanowanie wybranego folderu: User-agent: * Disallow: /images/ # Zakaz na skanowanie wszystkich adresów URL, które zaczynają się z /images: User-agent: * Disallow: /images
Stosowanie reguły Disallow bez wartości = oznacza brak takiej reguły:
# Pozwalamy skanowanie całej strony: User-agent: * Disallow:
Reguła Allow
Instrukcja Allow pozwala dodać wyjątki do instrukcji Disallow, którymi tworzymy zakazy, na przykład:
# Zakaz na skanowanie folderu, oprócz folderu wewnątrz: User-agent: * Disallow: /images/ # zakaz skanowania folderu Allow: /images/icons/ # wyjątek z zakazu skanowania powyżej Disallow dla folderu /images/
Przy takich samych wartościach, priorytet ma reguła Allow:
User-agent: * Disallow: /images/ # zakaz dostępu Allow: /images/ # anulowanie zakazu
Reguła Sitemap
Możemy również do pliku robots.txt dodać link na plik z mapą strony Sitemap.xml. Jako wartość Instrukcji Sitemap dodajemy bezpośredni link (z dodaniem protokołu http/https) do mapy serwisu:
User-agent: * Disallow: # Reguł Sitemap może być kilka: Sitemap: https://domena.pl/sitemap-1.xml Sitemap: https://domena.pl/sitemap-2.xml
Instrukcje Sitemap możemy dodać w dowolnym miejscu robots.txt, jednak najwygodniej będzie dodać ją na końcu pliku po pustej linii.
Jak znaleźć błędy w pliku robots.txt
Przetestować oraz sprawdzić poprawność dokumentu robots.txt możemy bezpośrednio w serwisach od Google. Sprawdzenie możliwe jedynie po aktualizacji pliku na serwerze lub hostingu, jeżeli Google nie znajdzie plik w folderze głównym naszej domeny – otrzymamy błąd w konsoli developera.
Poprawnie utworzony plik po testowaniu nie powinien zwrócić żadnych błędów:
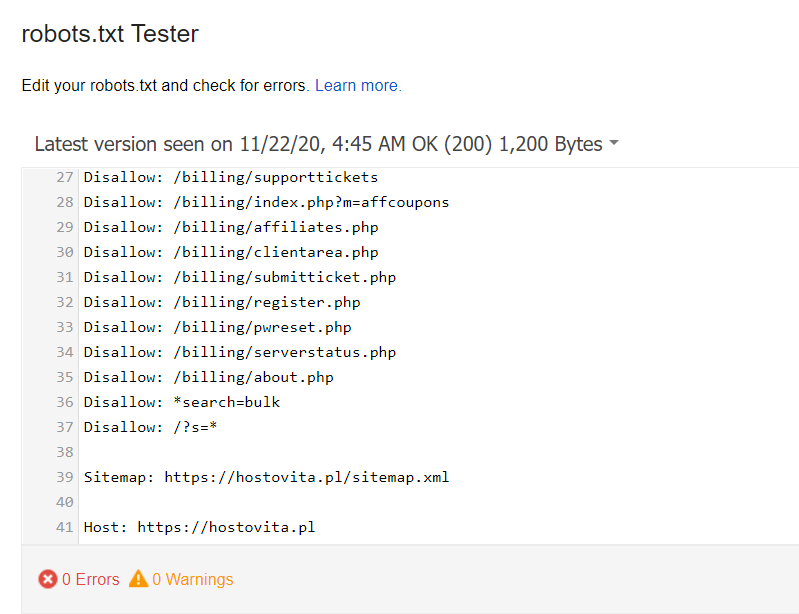
Narzędzia do testowania zawartości plików robots.txt:
- https://www.google.com/webmasters/tools/robots-testing-tool
- https://technicalseo.com/tools/robots-txt/
Wnioski
Plik robots.txt zawiera instrukcje tekstowe dla wyszukiwarek internetowych i jest przechowywany na serwerze w plikach strony. Jest wykorzystywany do zarządzania instrukcjami z pozwoleniami lub zakazami na skanowanie stron, rozdziałów, folderów lub innych parametrów.
Dodatkowo w pliku można dodać link do kopii głównej strony oraz link do mapy strony, co ma wpływ na pozycjonowanie strony w wynikach wyszukiwania. Instrukcje i reguły mogą być dodawane dla wszystkich lub wybranych robotów.
Podczas tworzenia pliku należy stosować pewnych reguł i dodawać instrukcji zgodnie z przyjętą składnią robots.txt.